TL;DR: my current stack
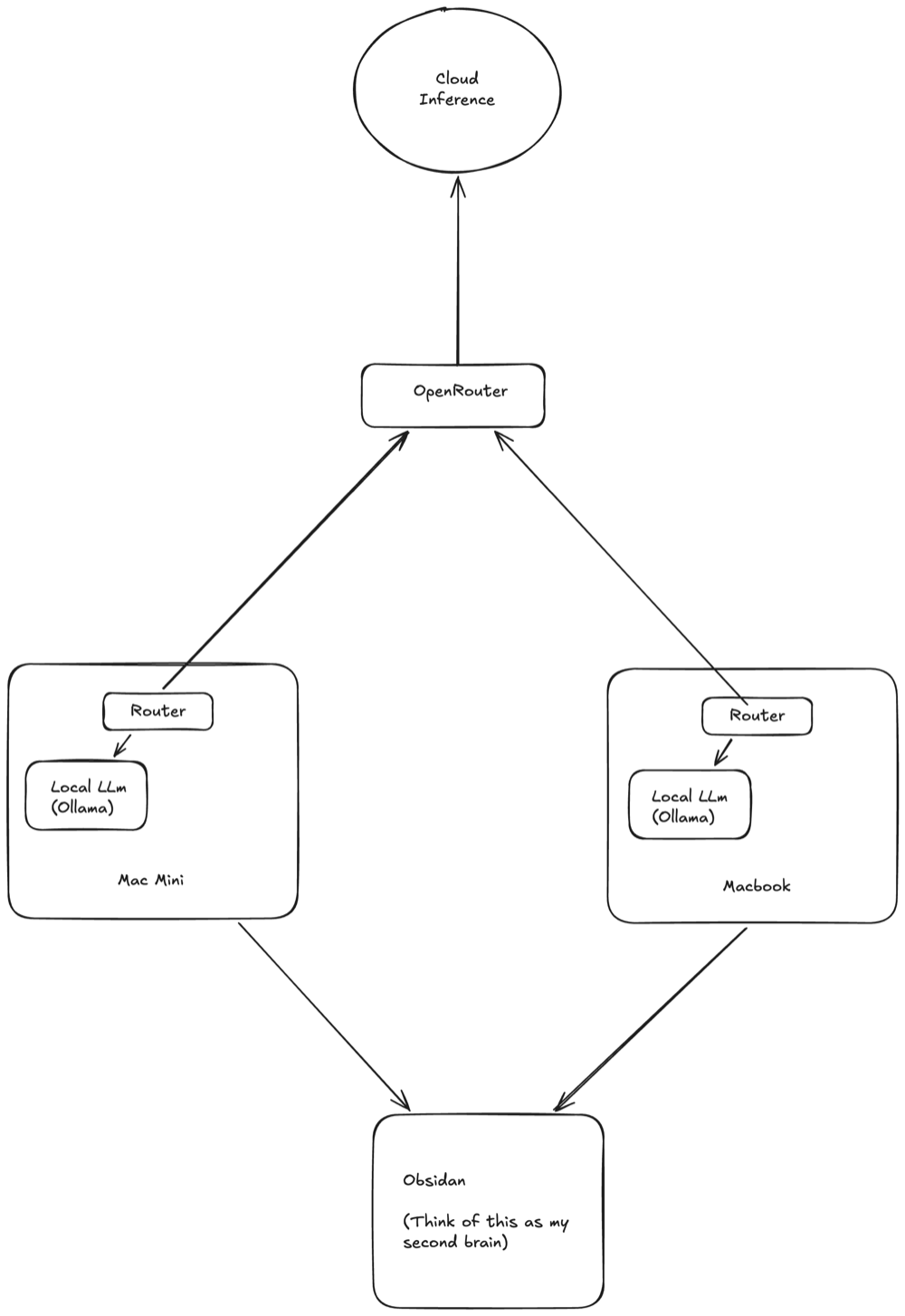
- Two machines. An M4 MacBook Pro (24GB) for work, and an always-on Mac mini for background automations.
- Local model is Gemma4-E2B-IT, run through Ollama on each machine.
- Cloud when I need more power: GLM 5.2 for coding, Gemini Flash for writing, DeepSeek V4 Flash for general automations, reached through OpenRouter.
- A custom router (slowly becoming a product called Standpipe) sits on each machine, redacts anything sensitive locally, and decides what stays local versus what goes to the cloud.
- Obsidian is the shared vault and the source of truth. My second brain.
- Harnesses are Claude Code on the laptop, and a Hermes agent on the mini wired to Signal.
- Capture is iPhone voice memos or Wispr Flow, transcribed straight into an Obsidian note.
I write a lot about owning the AI you use instead of renting it, so people keep asking what that actually looks like as hardware on a desk. Here is the setup I run every day. It changes hour by hour and I am still building most of it, so do not treat any of this as gospel.
The whole design comes down to one rule: keep inference on hardware I own whenever I can, and only spend cloud tokens when a local model genuinely cannot do the job. Everything below falls out of that.
It runs on two Macs and one Obsidian vault they both read/write from.
The Two Machines
The first is an M4 MacBook Pro with 24GB of RAM, and that number matters more than the chip. Apple Silicon shares one pool of memory between the CPU and GPU, so your RAM ceiling is also your model-size ceiling. 24GB means no 70B model running locally, full stop. I run Gemma4-E2B-IT through Ollama instead, a small instruction-tuned model quantized down to fit in memory with room left over for Claude Code and Obsidian. It is not as smart as a frontier model and it does not need to be. Most of what I ask in a day is small: rewrite this, summarize that, pull the action items out of a note. Gemma handles it on-device, and because nothing leaves the machine there is no network round trip to wait on.
Ollama is just the local runtime. It pulls the model weights down, runs them, and serves them on localhost behind an API, so anything on my machine can call a local model the same way it would call a cloud one. When the local model is not good enough, the request goes to the router, which I get to below.
The second is a Mac mini that stays on around the clock. Agents are long-running processes, not apps you open and close, so they need a host that is always awake. My laptop sleeps and travels. The mini does not. It runs a Hermes agent wired to Signal and to the same Obsidian vault, so I can text it like a contact in my phone and it answers with the full context of my notes behind it. The mini also runs the bulk of my background automations, and since those fire all day, it is where cloud cost adds up and where the router earns its keep.
Both machines run the same two things: a local model under Ollama, and the router that decides whether a request stays local or goes out. Neither box is special. The router is the same on both, and so is the vault, so I can sit down at either one and the rules about where my data goes do not change.
The shared piece is Obsidian, and it is the part I am always tweaking. Underneath, it is a flat folder of markdown files, nothing exotic, which is the reason it works as the source of truth. Every agent reads plain text out of one vault instead of each tool inventing its own private memory. I pay for the sync so it propagates across machines in seconds, and because the context lives in files I own, there is no copy of it sitting in someone else's account.
The Router Is the Brain
The router is the part people ask about, because it is what gives me control over my prompts instead of handing them blindly to whoever is cheapest.
It runs a small classification step locally before anything else happens, what I call its inference plane. Every request gets looked at on two axes. The first is sensitivity: does this contain my name, a client, an email, anything personal. The second is difficulty: can the local model handle this, or does it need something bigger.
Sensitivity decides what is allowed to leave the machine. The router scans the text for personal data, names, emails, client identifiers, the obvious stuff, and then does one of two things. If the request can survive it, the router redacts those spans, swaps in placeholders, and only then sends it out through OpenRouter. If it is too sensitive to redact cleanly, it never leaves at all and the local Gemma model takes it. The honest limitation: redaction is not perfect and a classifier will miss things, which is exactly why the truly private work stays fully local instead of trusting a filter to catch every leak.
Difficulty decides cost. For anything that does go out, OpenRouter is the gateway. It fronts dozens of providers behind one API, so the router can send each job to the cheapest model that can actually do it and swap models with a config change instead of a rewrite. In practice that is GLM 5.2 for code, Gemini Flash for writing, and DeepSeek V4 Flash for general automations. The point of splitting it this way is that no single vendor ever sees the full stream of what I type.
We are thinking about releasing this router to a wider audience. If that is something you would want to run yourself, comment or reach out.
How the Work Flows
The day starts with my voice. I talk into voice memos on my iPhone or Wispr Flow, the audio gets transcribed, and the transcript lands as a markdown note in Obsidian. That note is the input to everything downstream.
From there I hand it to an agent harness, either the Hermes agent on the mini or Claude Code on the laptop, and the router decides per request where each step runs. The harness turns a rambling transcript into the actual artifact: a script, a company update, a schedule, meeting notes, whatever I was thinking out loud about on a walk.
Models keep getting better and I swap them out constantly. The harness that manages the context and the router that decides what is safe to send do not change when I do, which is why they are the parts I actually invest in.
Every Skill, By Hand
The part I am most careful about is skills, the bundled instructions and tools I let an agent load. This is where most people are going to get burned, so pay attention.
Prompt injection is the core problem. An LLM cannot reliably tell the difference between instructions from me and instructions buried in the content it reads. Anything that lands in the context window can steer the model, and once an agent has access to my notes and my Signal, one poisoned instruction can exfiltrate or wreck a lot in a hurry. So I read every skill line by line before I let it run, and I write most of them myself.
Reading a skill once is not enough, though, because a skill can point at a URL, and a URL is mutable. It can be benign the day I approve it and malicious a week later, after I have stopped looking. That is a time-of-check-to-time-of-use problem, and it is the kind of quiet supply-chain swap that walks straight past human review. So I am building a check that hashes every link in a skill locally and verifies that hash on every run. If the target changed, the skill does not run. The hash catches the swap even when I would not.
It is rough and half-built and will probably look different by the time you read this.
Two Macs, the same router on each, one Obsidian vault everything reads from, and a rule that I read the skills before they read my data. If you run something similar, or you see a hole in this I have not thought about yet, tell me in the comments. I would genuinely like to hear it.
If you liked this post, subscribe to get new ones straight to your inbox.
Subscribe on Substack