AI agents are selfish.
I use that word deliberately because I want to invoke something human, something you can feel rather than just analyze. When a little kid won't share their cookies. They're not trying to be malicious; they just don't know the importance of sharing yet. Right now, every agent stack in production resembles that kid. Each one is designed to perform a specific task for a single user and does nothing else. Claude Code can't talk to Codex. Gemini has no way to pull the state out of an OpenAI flow. Although agent-to-agent protocols (A2A) are emerging, they are still early and don't yet support meaningful cross-vendor coordination. Part of that is because agents don't know anything outside of themselves. This is part of their selfishness.
Take a look at the diagram below. If you are working with multiple models, what happens when you are working on the same problem? Those boxes are separated, each unaware of the other model. And the agents within are unaware of one another. If Agent 1 is querying a SQL database, Agent X might not know and waste compute time doing the same output with a different process. We still need a driver to guide all the agents because they won't talk to one another independently.
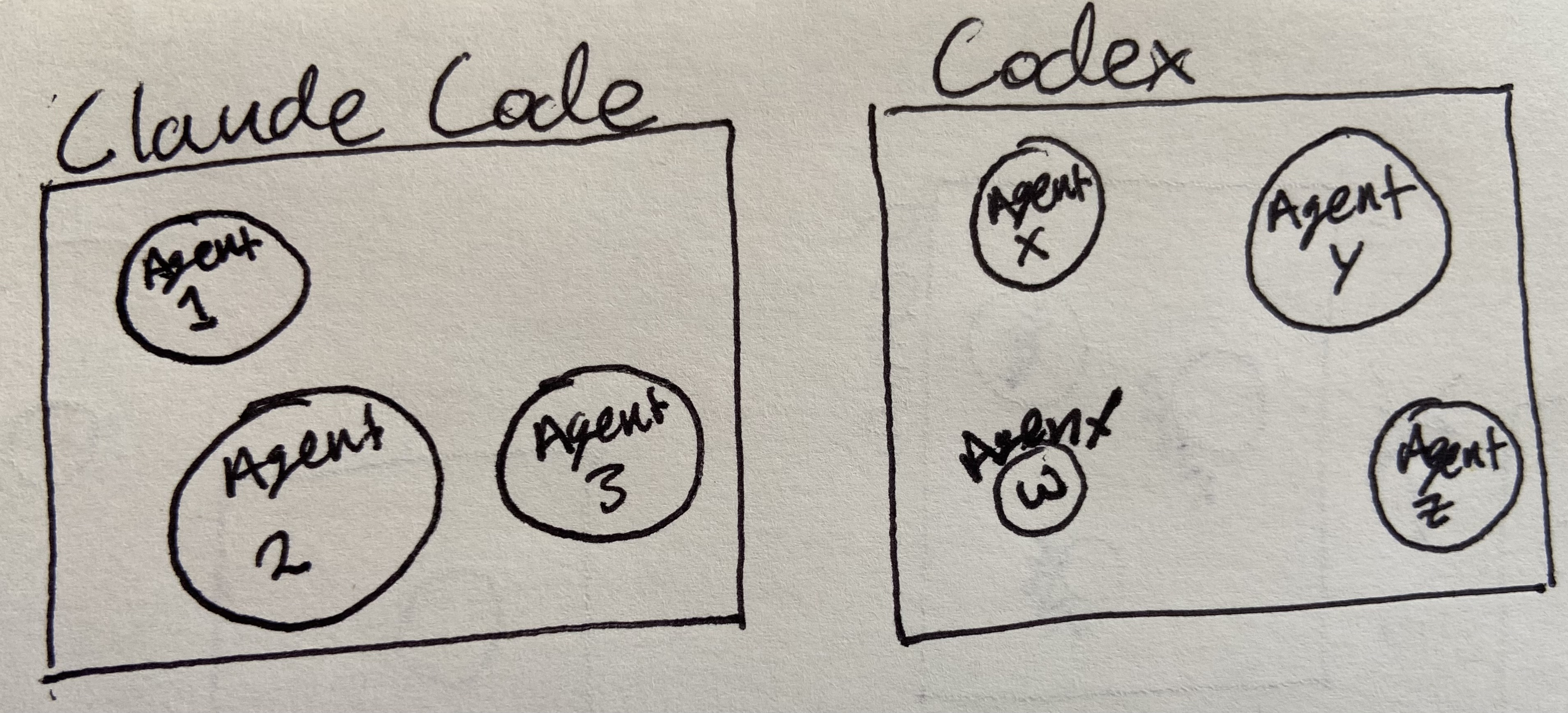
Diagram: The current agent stacks do not have cross-model collaboration nor cross-agent collaboration.
And that driver is you, the human reading this blog (hi friend!). You are the one who prompts the model. You are the one hopping on the Slack call at midnight. The one who knows what every tool in the stack does and the order they need to be called. The agent does its job and stops. You do the rest. And the "rest" is typically fighting Claude and ChatGPT to get the right output. We have all been there; you must refine every prompt, repeat yourself, until you get the result you want. And yet, we are constantly hearing "adopt, adopt, adopt."
AI Agent Framework
I was on a call recently where a company had gone all-in on AI adoption. Good intentions, a real budget, and a genuine belief. They were replacing their SaaS stack with custom agent-powered tools. A custom CRM here. A custom workflow automation there. And what I kept noticing was that none of these things talked to each other. They'd replaced the problem of many poorly integrated SaaS products with the problem of many poorly integrated agent products, and somehow felt like they'd made progress.
There's a real seduction to the current generation of tools. When an agent dynamically surfaces information you'd normally have to write SQL to get, that genuinely is magic. I don't want to downplay that. But this magic has its limits. The moment you need integration between two of these tools on a task is when you realize that the human in the room is still doing the most complicated part.
What if, instead of simply adapting AI agent tools to old SaaS products, we drew inspiration from biology? What if agents could be influenced by their environment, functioning similarly to the cells in our bodies?
What if We Copied Biology?
Cells don't communicate the way our agent stacks do. Not even close.
A single cell is continuously receiving and integrating mechanical, chemical, electrical, and paracrine signals from its environment all at once. It isn't taking turns; it doesn't wait for a response before acting, nor does it summarize previous messages before feeding them into a new context window. It's integrating everything, all the time, and making weighted decisions that change based on what else is happening.
And then there's the environment itself. For a long time, biologists thought the surrounding tissue was passive scaffolding. Structural protein jelly that holds everything in place. What turns out to be true is that the biological scaffolding is an active participant in cell signaling. The stiffness of the matrix matters. The porosity matters. Cells can send mechanical strain across them to communicate with other cells over long distances. The infrastructure is shaping the cells and the message itself.
Now think about what we call "context" in an agent system. It's a transcript. A log. Prior messages are concatenated and fed back into the input. It doesn't modulate the agent's behavior based on state. It doesn't carry mechanical information, metaphorically speaking. It just sits there. It gets compressed and eventually rots.
The context layer in agent architecture today is the biological scaffolding, before anyone understood what it actually did.
Nondeterministic Agent States
Several biological models align with the problems I've observed in agent architecture, and the one that resonates most is that of attractor states.
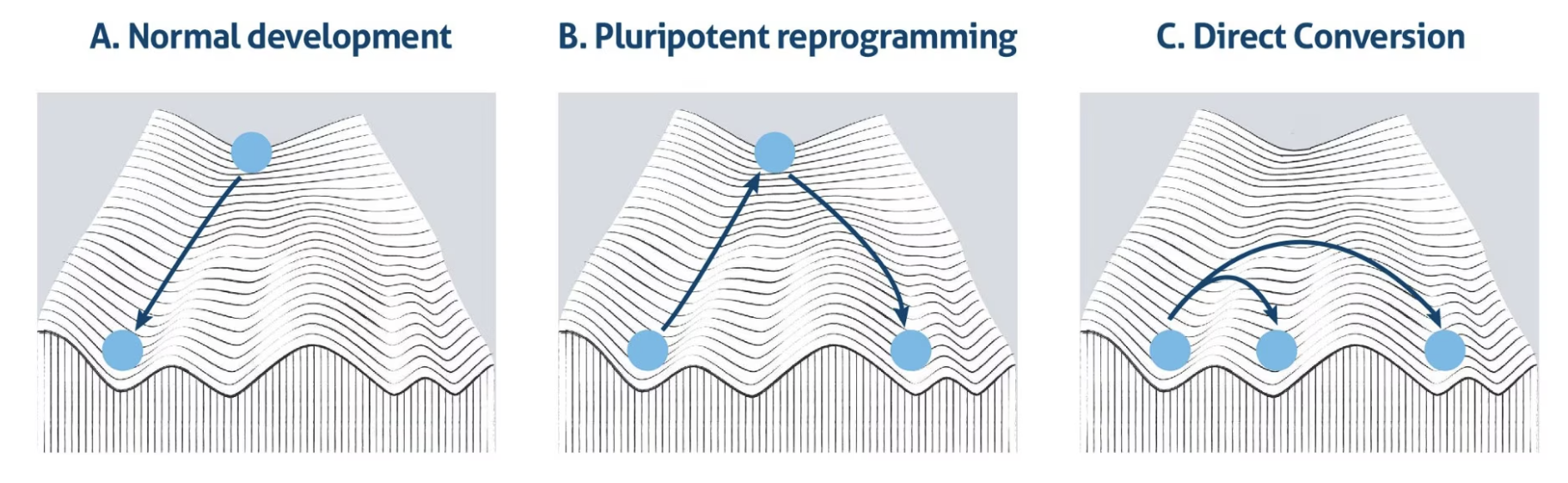
Diagram: Waddington's landscape represents cell differentiation, where a cell (a ball) rolls down a branched, sloped landscape (valleys and ridges).
Waddington's landscape is the classical illustration [1, 2]. Picture a ball sitting at the top of a hill with peaks, valleys, and troughs running down it. The old assumption was that the ball would roll into a valley, and the peaks would ensure the ball stays in that valley. It was predetermined.
Cell fate bifurcation [3] tells a different story. At key decision points on the landscape, the ball reaches a fork where multiple valleys open up. Which valley the cell commits to isn't determined in advance. It's shaped by stochastic fluctuations in gene expression, by the signals arriving from the environment in that exact moment, and by the internal state of the cell. Two genetically identical cells in identical conditions can end up in different valleys. The path isn't on the map. It's discovered in the rolling.
Agents don't do this. When you run a capable agent on a hard problem, it tries its best to answer the goal of your prompt. It follows a path. It doesn't build or look for a new path. The story of Anthropic's Mythos finding issues in Firefox is the exception that proves the rule [4]. Because Anthropic was able to run a raw model on its own infrastructure and take up the associated costs, the model was able to wander. It spent what was almost certainly a very significant amount of compute time following weird paths, pursuing different hypotheses, and going down rabbit holes. Over the course of a week, it found a deep browser vulnerability no human would likely have found in any reasonable timeframe.
The compute budget that made that possible isn't available to the rest of us. We don't know what their agent harness looked like from the outside. It almost certainly wasn't a single flow. But the point is: the wandering was the work. The non-determinism was the feature. We need to keep that non-determinism, and businesses need to start using it as a feature tool rather than a bug.
Leader-Follower Dynamics
There's an engineering pattern that applies here: Leader-follower replication. When a leader node fails, an election happens. The next node in line takes over. The old leader, if it recovers, goes to the back of the queue. It's elected, which makes the system resilient. It's already implemented in tools we use today. Kafka uses it. Raft and ZAB are built on it. etcd, Consul, CockroachDB, MongoDB, and Redis all depend on it.
Leader-follower replication also occurs in biology. The frontmost cells, known as leader cells, sense the environment. Follower cells trail behind the leader cells. But the roles aren't fixed. A follower cell can become the new leader through biochemical and biomechanical forces [5]. There's constant turnover. The system is resilient because leadership is a state, not a predetermined identity.
Current agent harnesses don't use any of this. If the planner agent dies, the session is dead. If a subagent goes offline, you're not getting a response. There's no failover, no redundancy, no election. We developed AI agents to be one agent for one person. It is a static hierarchy that is fragile, unlike biological systems. Now we are starting to have sub-agents work under a planner agent, but this is not how distributed systems work. It isn't even how teams of humans work. I've seen firsthand why we needed to implement failover in software infrastructure. If a server dies, you need that data to quickly move to a server that is online with little to no latency.
Why don't agent harnesses use the leader-follower replication model, as seen in biology and infrastructure management?
The issue is you'd have to build an agent harness from the ground up. A lot of what Anthropic and others are building is more like an event bus system. You send a message, and it goes to a specific number of recipients through a bus. This mimics aspects of a distributed network, but the path in an event bus is deterministic. In a true distributed network, the path is emergent.
For biology, evolutionary pressure and redundancy are two of the most important aspects to get us where we are today. We are already seeing evolutionary pressure in the software lifecycle. The flow used to be: write code, write tests, push to GitHub, deploy, observe. The volume of code that agents can produce has created a bottleneck at the pull request layer. You still need a human in the loop.
What if AI Agents Learned?
There's a question underneath all of this that I keep coming back to: what does it mean for agents to actually learn from their mistakes?
Not fine-tuning. Not feeding a dataset to a model. Genuine learned capability. The kind where, if you had a swarm of specialized agents working together on a hard problem, and the swarm made an error, the error would change how the swarm behaves on the next attempt. Like cells that carry the memory of environments they used to inhabit. When cells grow in a stiff environment and are then moved to a softer one, they behave as if they're still in the stiff one. Or the memory we have. If you burn your hand on a stove, you know not to touch the stove again.
We have nothing like this in agent architecture. The model's weights are frozen. Fine-tuning is expensive. Context rots. And the clone factor, the ability to spin up ten thousand copies of an agent that works, stops working once the learned information is rotten. If an agent is spun up with amnesia and has no way to gain knowledge as humans do, then that agent becomes useless.
If we ever figure out how to train models quickly and cheaply on specific tasks, the clone factor becomes the most important variable in the whole problem. A human takes 25 to 30 years to reach a genuinely high level of contribution, if they ever do. A working model spins up in seconds. The thing standing between that and something genuinely transformative isn't the model itself. It's the absence of any architecture that lets the copies talk to each other, learn from each other, and reshape the landscape they're all traveling through. That's a signaling problem.
Signaling is the Intelligence
The thesis I have come to from all of this is simple to state and hard to act on: biology didn't evolve intelligence first and add signaling later. The signaling is the intelligence. And when I look at what made tools like Claude Code feel powerful, it's not the model. It's the signal loop. The chain of thought. The ability to take action and observe the consequence. The model was always capable. What made it useful was giving it the ability to receive signals from the environment and act on them recursively.
We are at the very beginning of understanding what that loop should look like at scale. Most of the movement happening now around context layers, governance, observability, that's people starting to feel the shape of the missing thing, even if they don't have a name for it yet.
Whatever gets built will probably not look like what anyone is currently describing. The cancer problem in biology is a useful parallel. The answer to cancer almost certainly isn't found purely in cancer research. It's more likely to come from some basic biological discovery that makes something else click. The answer to agentic scaling isn't found in making the models bigger. It's probably found somewhere in the question of how they signal each other, and what kind of infrastructure allows those signals to do real work.
That's the question I can't stop asking. Not "how smart can a model be," but what happens when the signaling catches up to the intelligence that already exists.
Citations
[1] https://www.ptglab.com/news/blog/cell-fate-commitment-and-the-waddington-landscape-model/
[2] https://www.nature.com/articles/nrm3543
[3] https://www.nature.com/articles/nrg.2016.98
If you liked this post, subscribe to get new ones straight to your inbox.
Subscribe on Substack